Project Database
|
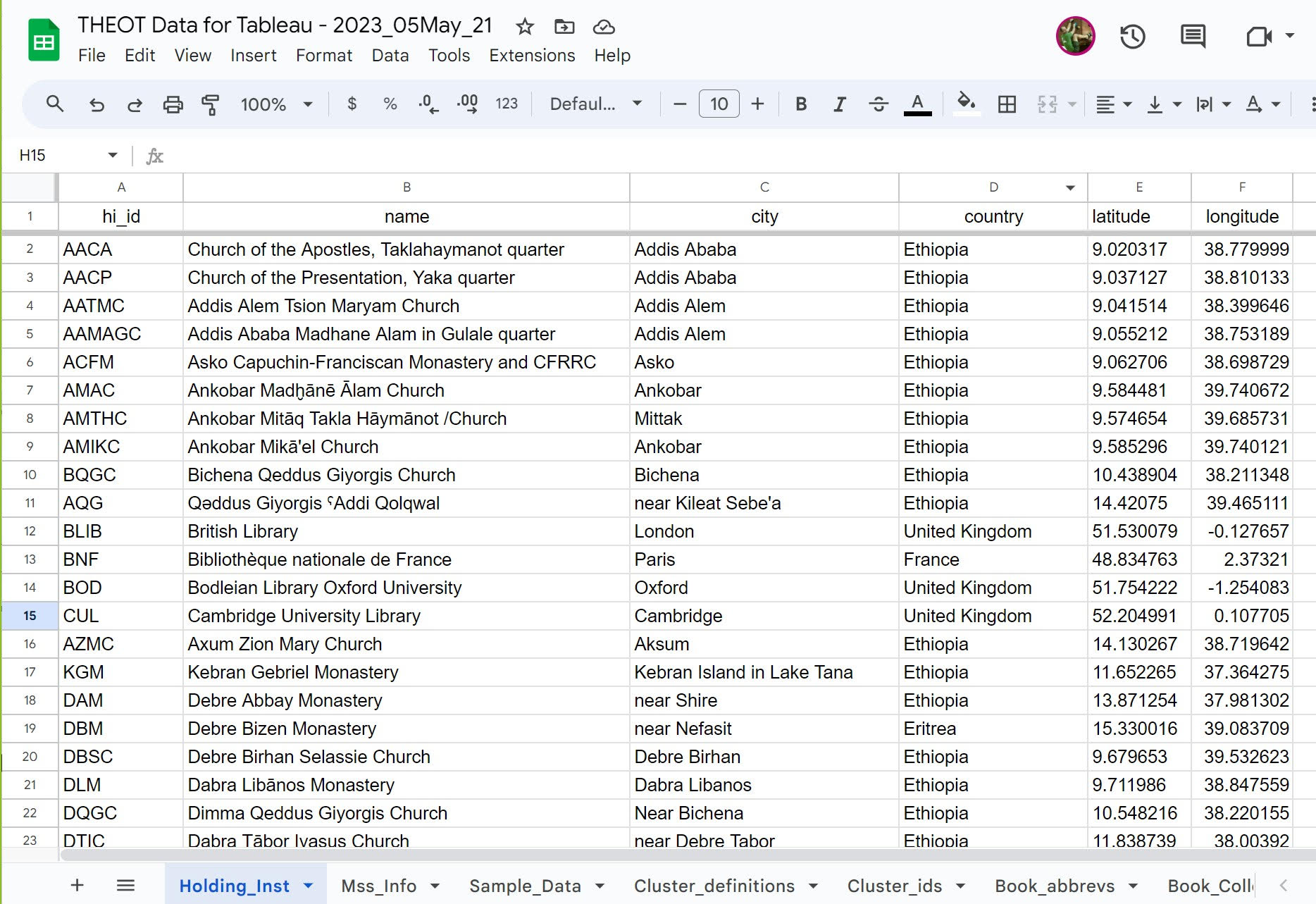
This tab is organized by holding institution. It contains information regarding the institutions that hold the manuscripts used in this study. These include columns for a unique “holding institution identifier” (hi_id), the name of the institution, city, country, and columns for latitude and longitude.
|
|
This tab is organized by manuscript. It contains information regarding the manuscripts used in the study. These include columns for a unique “manuscript identifier” (ms_id), primary and secondary sigla for the manuscripts, the holding institution identifier, and various columns relating to a description of the the dating of the manuscript.
|
|
This tab is organized by book of the Ethiopic Old Testament (book_id). Each of the following columns contains information about the sample of manuscripts used in the THEOT study and about the extent of the text transcribed for the study. These include columns identifying the book under study, the number of manuscripts, a list of the specific manuscripts used, number of words in the base text of the sample, the total words in the book, the total number of words in the sample, the calculated percentage of the book in the sample of the study, the number of data rows, the total number of data points represented by the number of manuscripts multiplied by the number of words in dots and bars grid.
|
|
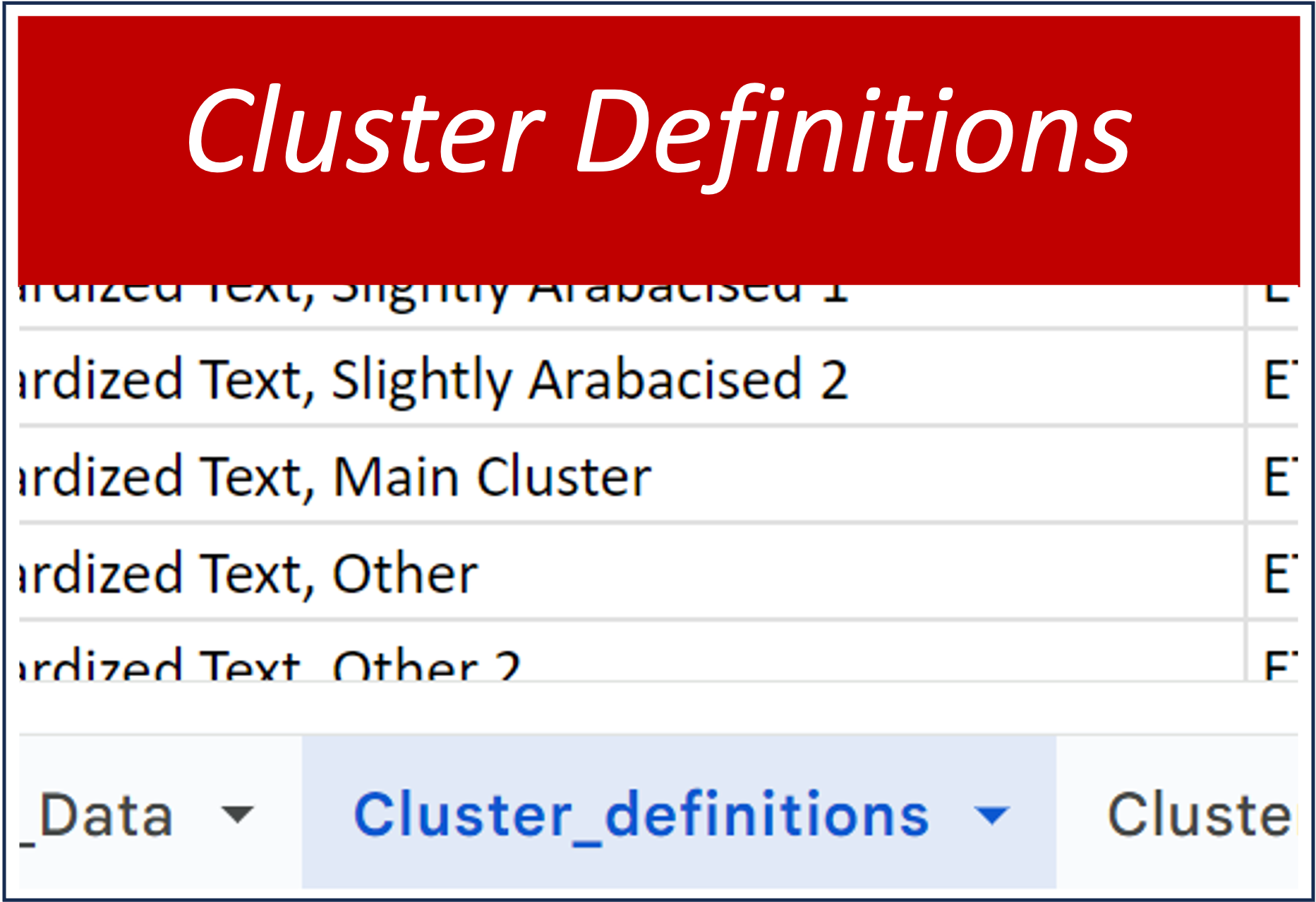
This tab is a definition table that sets forth a naming convention for cluster identification (clus-id) and various ways of describing the clusters. These are used to designate the cluster membership in a specific old testament book for the various manuscripts in our study. In the next tab, the specific manuscripts will be labeled with the cluster definition appropriate to the book being studied. |
|
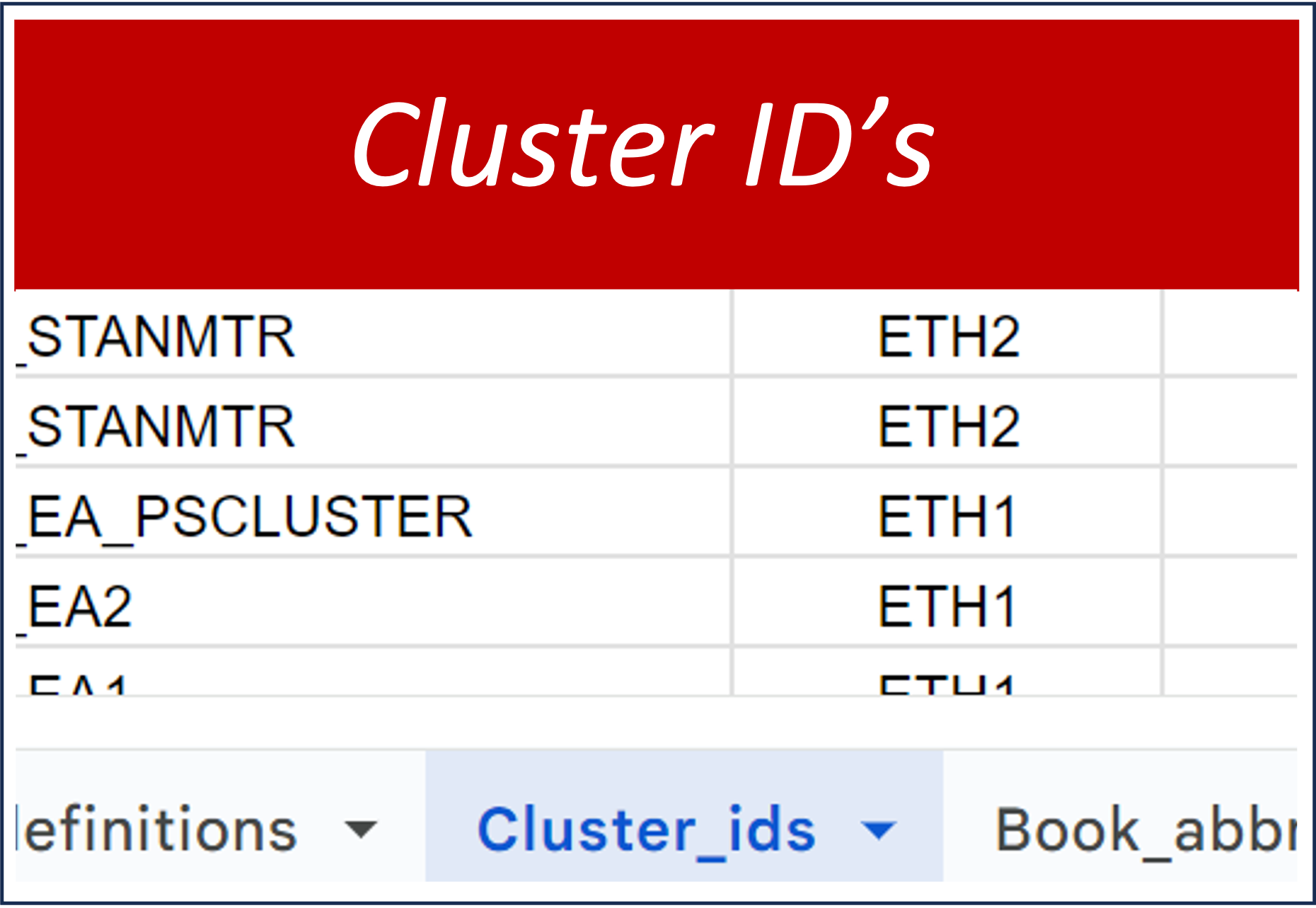
This tab is organized to provide information about the clusters to which the various manuscripts belong in each book study. The primary columns provide book_id, ms_id, and clus_id. Secondary columns indicate witness number (witness_no) and cluster number (cluster_no), which are book specific, i.e., not uniform from book to book.
|
|
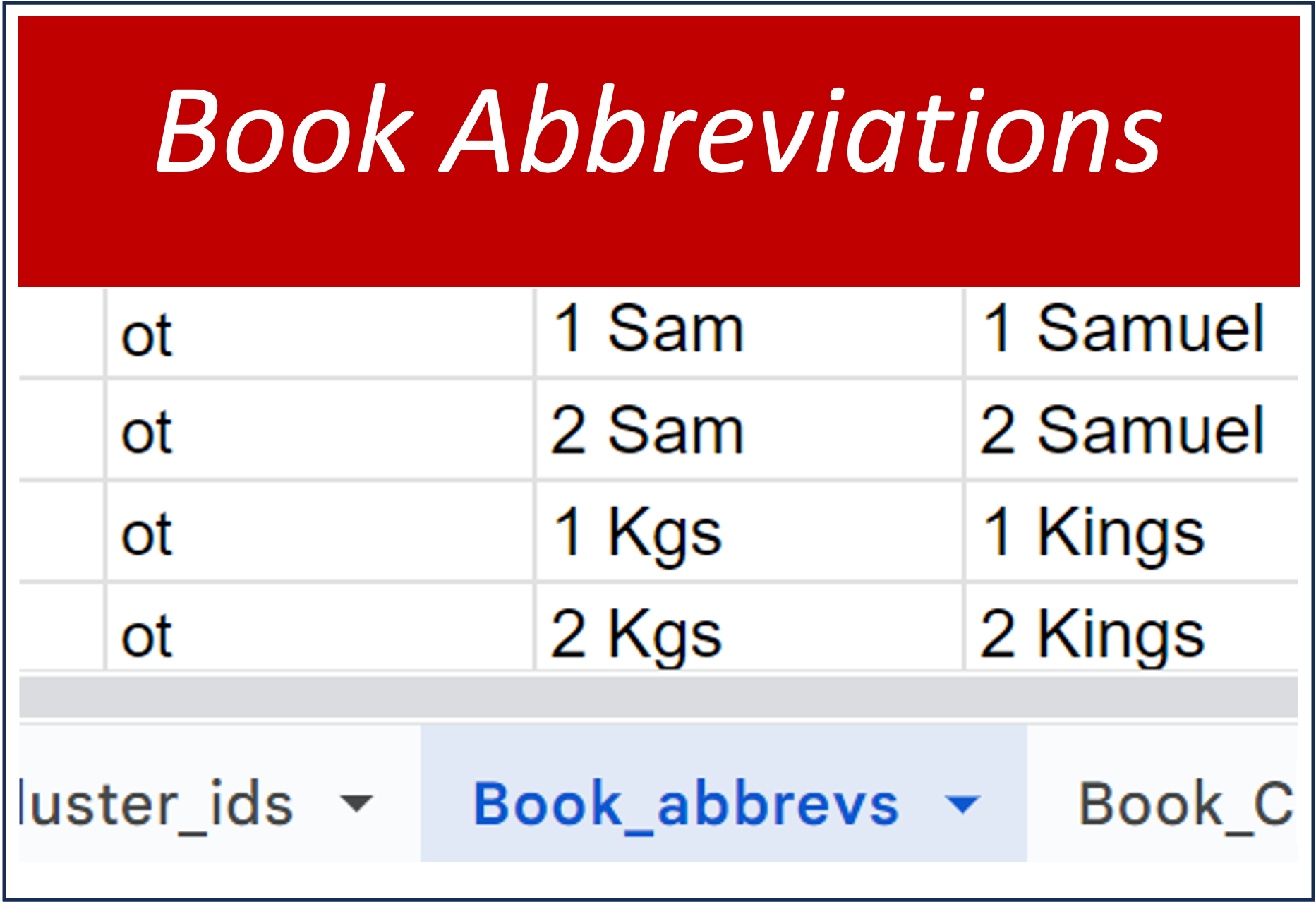
This tab is also a definition table. It provides the standard SBL abbreviations for the books of the bible, which we have adopted for our work and data. These are clarified further with columns indicating membership in the conventional canonical categories of Old Testament New, Testament or Apocrypha.
|
|
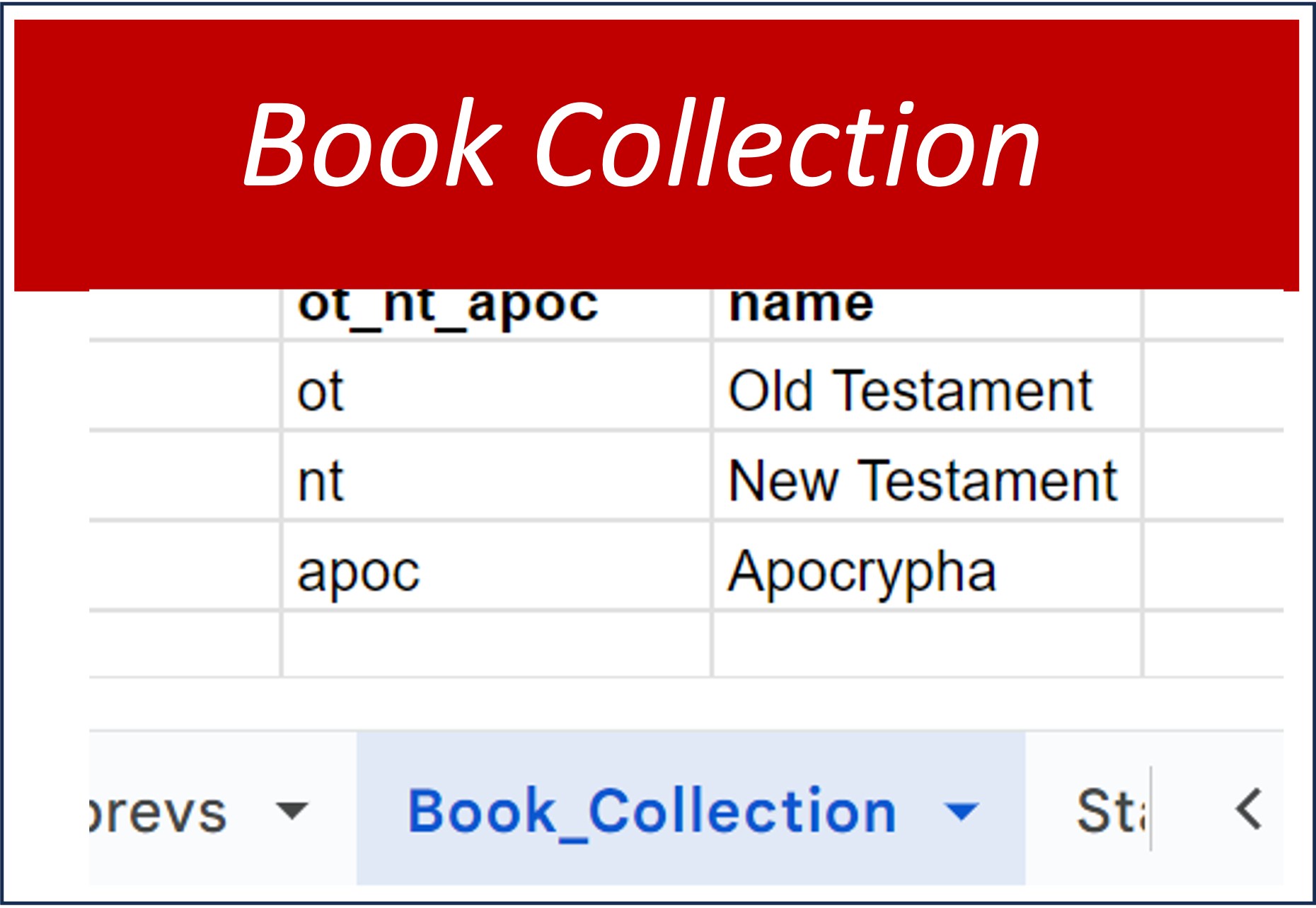
This tab is another definition table which simply provides a fast and easy approach to grouping data under these headings . |
|
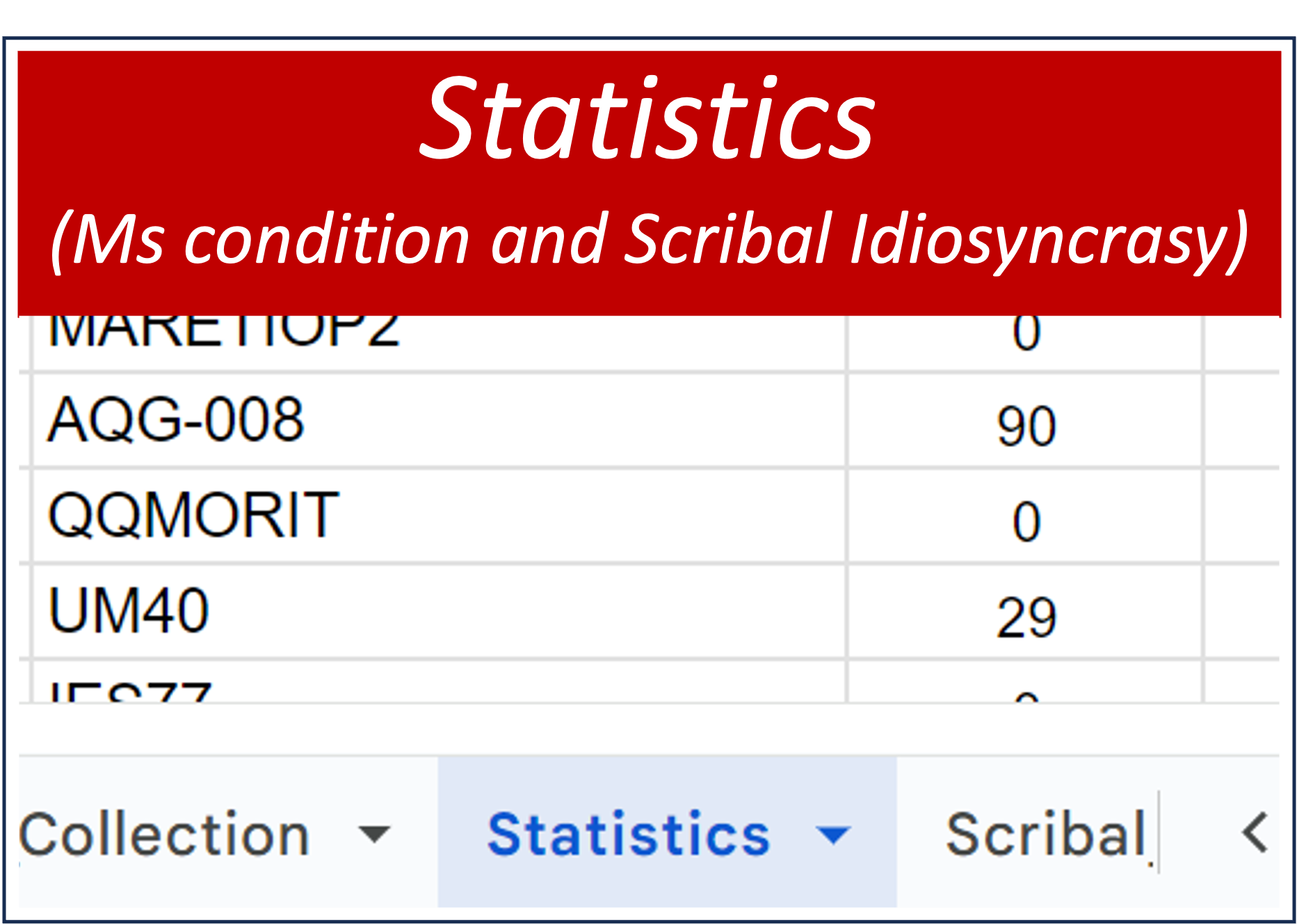
This tab contains detailed statistical information related to two things: 1) manuscript condition (i.e., the presence, absence, and/or legibility of text in a manuscript); and 2) scribal idiosyncrasy.
|

|
This tab contains detailed statistical information related to the interventions by secondary hands to change and correct perceived errors. The columns provide information on the quantity and details of the interventions specific to each manuscript in the study. This category of data is exploratory and has been carried out on only one book (Judges), but provides a proof of concept for the idea of visualizing the phenomena of scribal intervention.
|
|
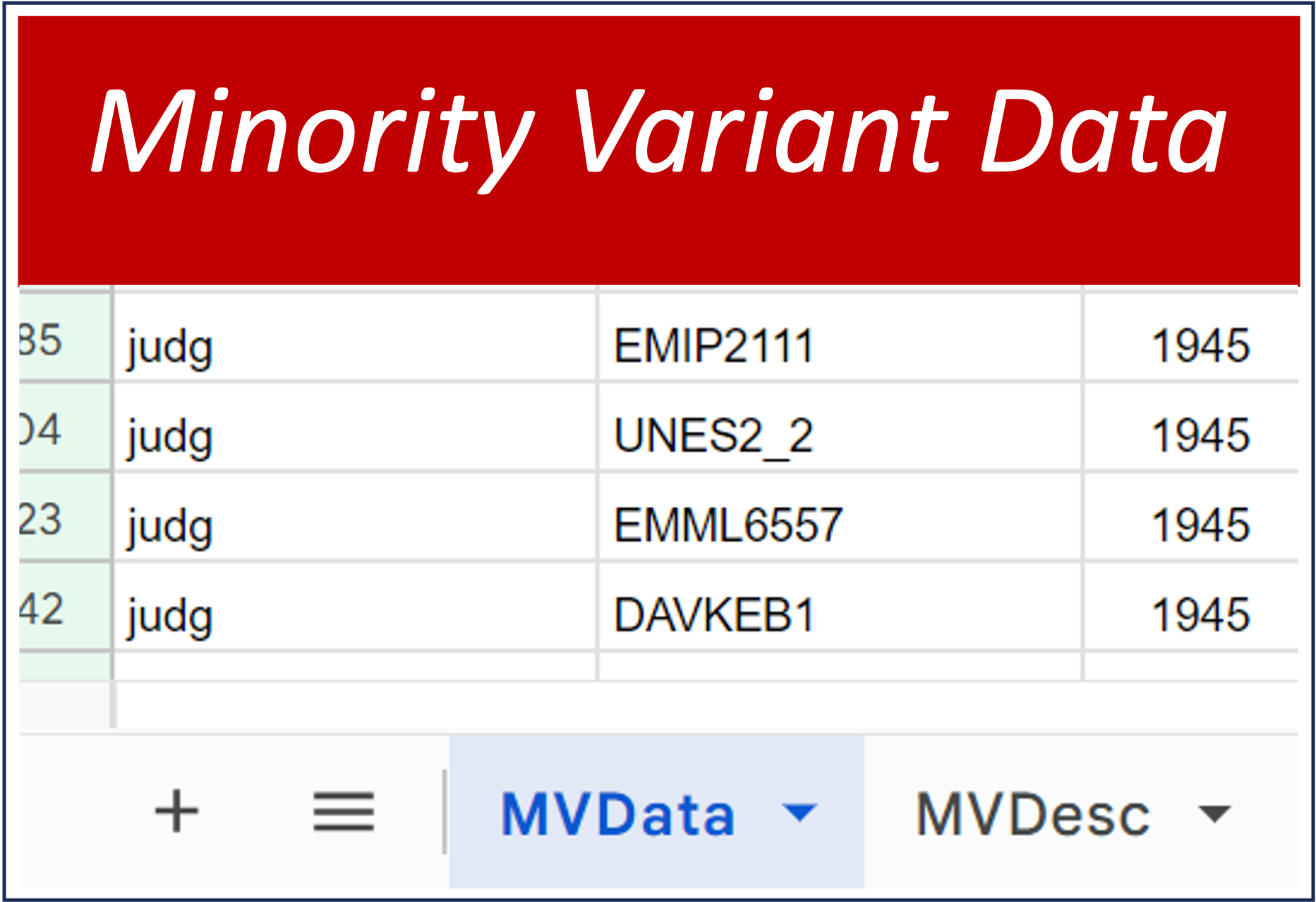
This tab, on Minority Variant Data, and the next one, on Minority Variants Descriptions, contain detailed statistical and philological information about shared minority variants among the manuscript copies of a book. This tab is organized around book id, manuscript id, and the presence or absence (specified by a one or a null) of minority variants in specific columns of the dots and bars text matrix.
|
|
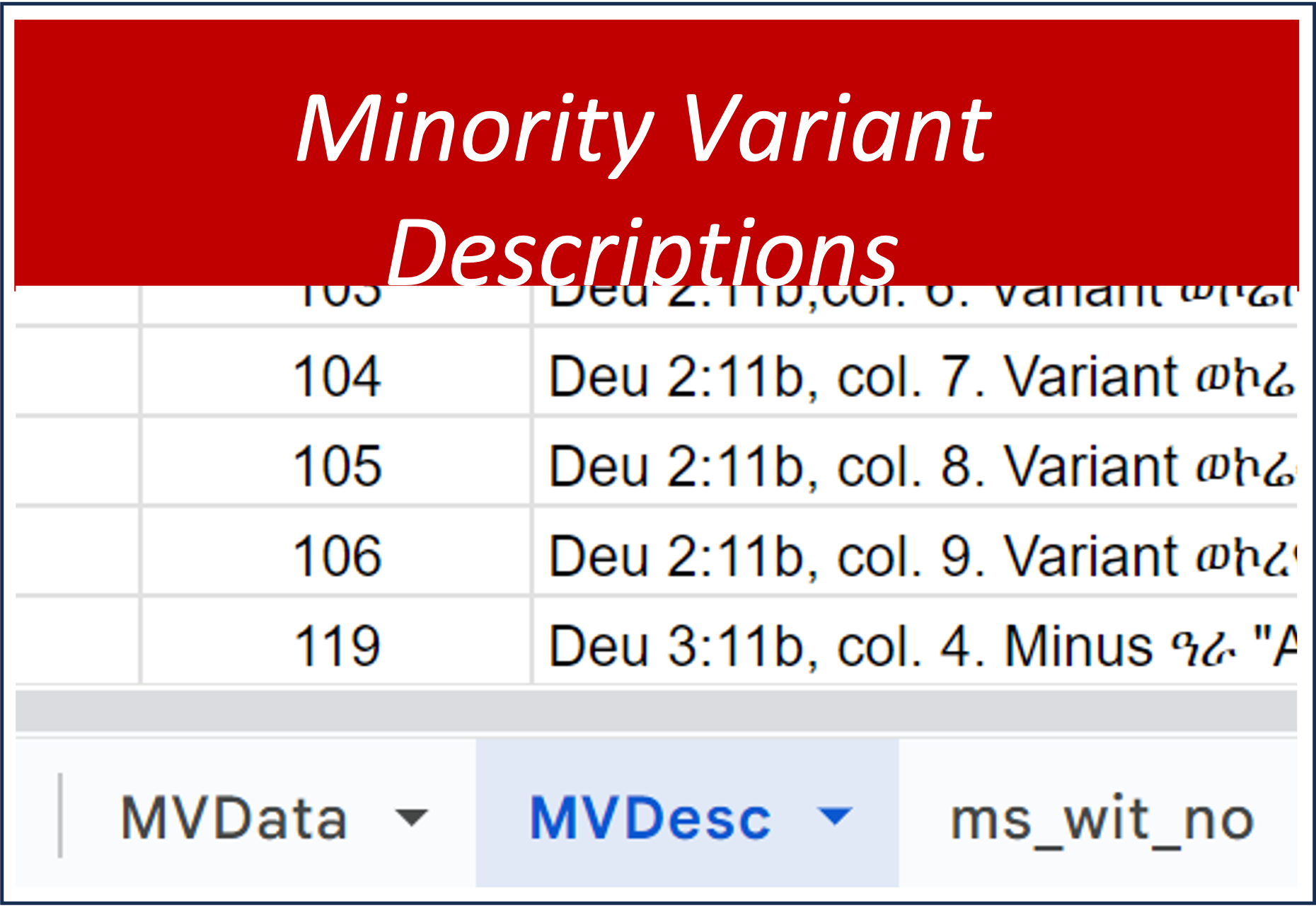
This tab, on Minority Variant Descriptions, goes with the previous one on Minority Variant Data. Whereas the previous tab contained only statistical information about the presence or absence of a minority variants, this tab provides only the listing and description of the minority variants. This tab is organized around book id, and tvu number. But the column labeled tvu specifies a locus where multiple manuscfripts share a particular minority variant. The most important column, then, is the one labeled minority variant description (mv_desc) a description of the minority variant itself.
|
|
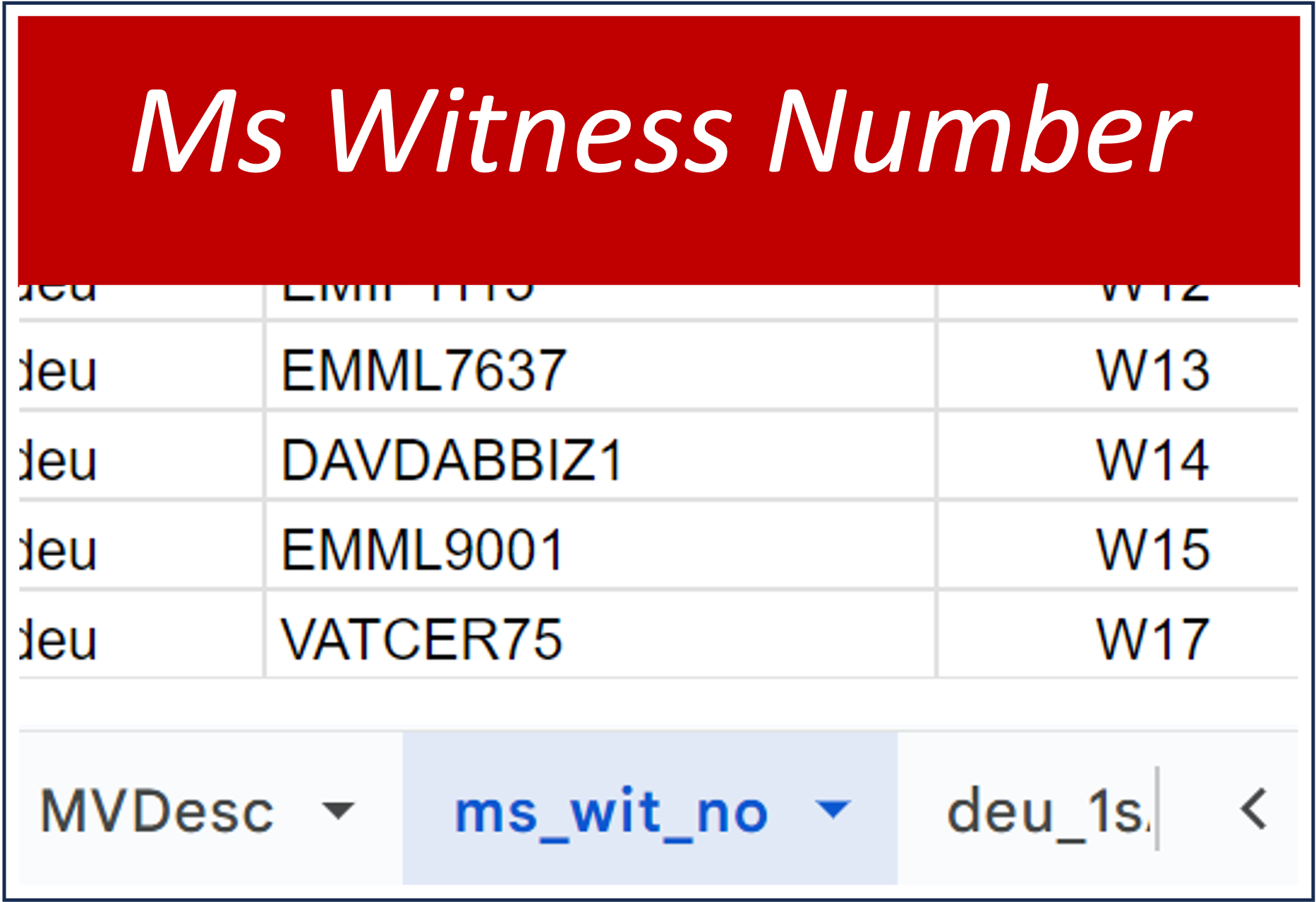
This tab merely specifies the witness number assigned to each manuscript in the study. Since there is no consistencey maintained around which manuscripts are assigned which witness number, this information has no significance beyond the specific book it is in. It is, however, useful to be able to correlate manuscript sigla with witness number for each book study. |
