Materials for the
Study of Ethiopic
Esther
We...
Turn text into numbers.
Identify patterns in the numbers.
Turn numbers into stories.
Ethiopic Esther
Stuffs1-goes-here
Aligned
Texts
Texts
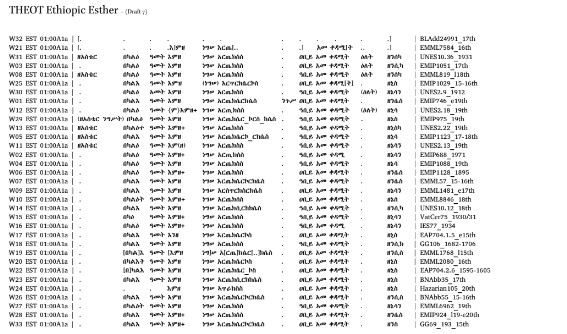
The PDF is a copy of the document file in which we aligned all the words of all the manuscripts in this study. Click the image on the left to download the pdf file. Click the image on the right to see a video explaining how this data was produced or processed.
Variants
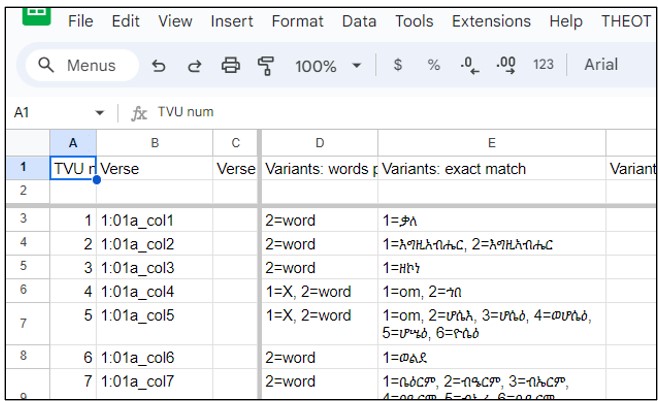
The spreadsheet shows the data produced by the THEOT script labeled “create database of variants”. Click the image on the left to open a copy of the spreadsheet. Click the image on the right to see a video explaining how this data was produced or processed.
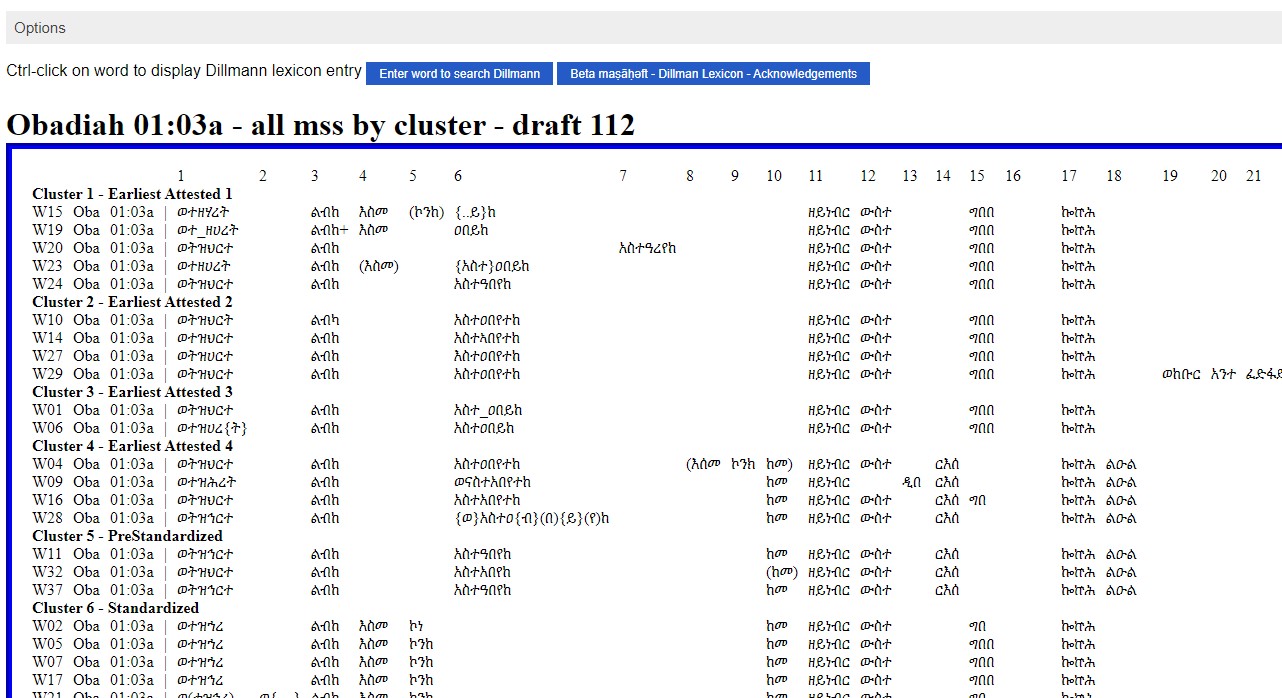
Words
Profile
Match
Profile
Match
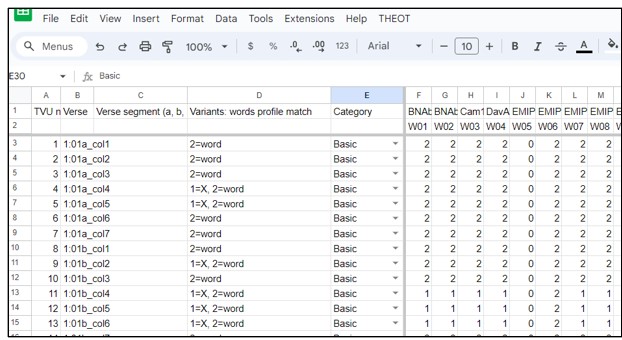
The spreadsheet shows the data produced by the THEOT script labeled “process database of variants”. Click the image on the left to open a copy of the spreadsheet. Click the image on the right to see a video explaining how this data was produced or processed.
Dendrogram
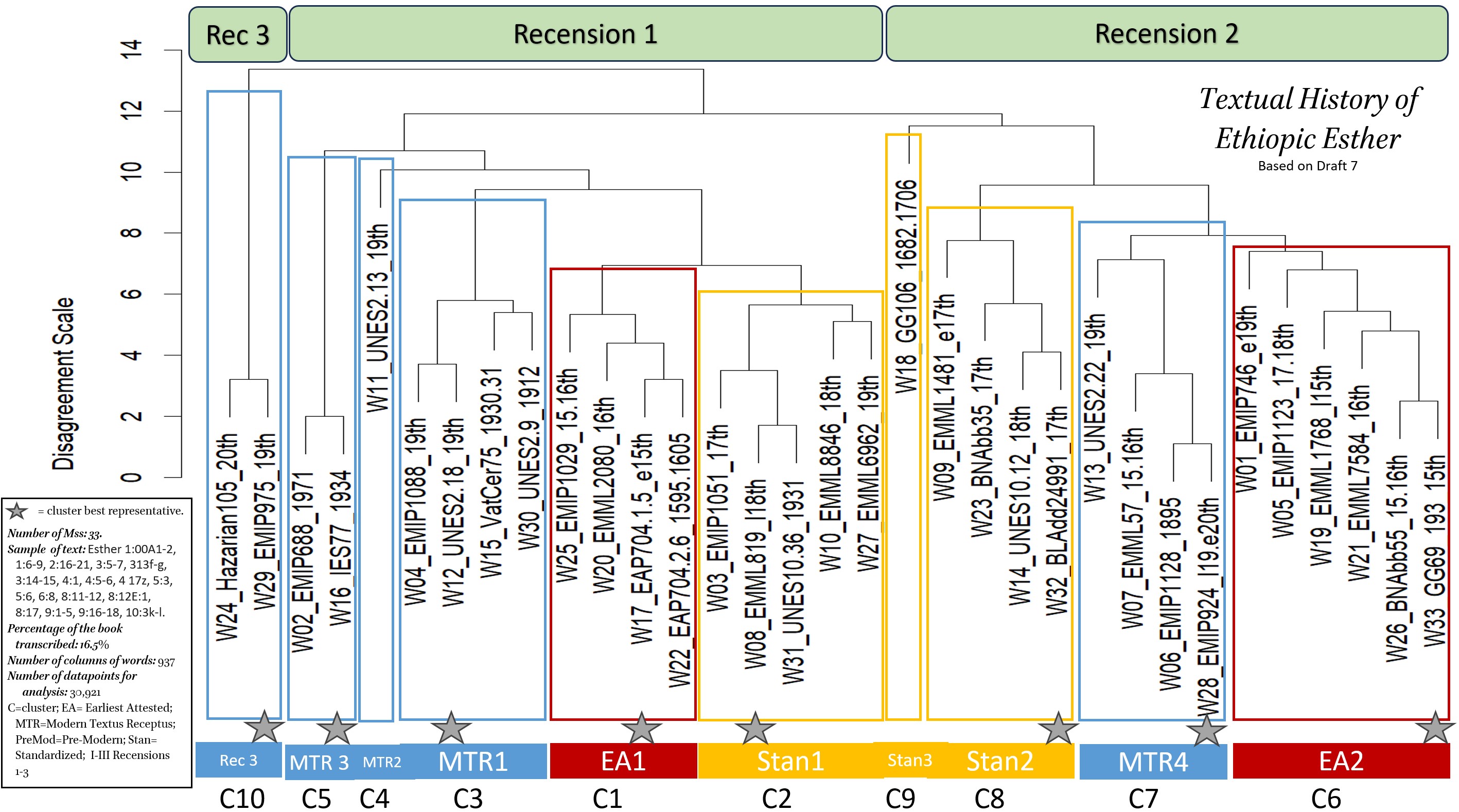
The jpeg shows the Dendrogram produced by feeding the R file and a CSV (comma separated values) file into the R program to generate a dendrogram. The colored boxes and stars represent our interpretation of the dendrogram, and become our working hypothesis for investigation of the book. Click the image on the left the dendrogram. Click the image on the right to see a video on THEOT Dendrograms and How to Use them.
THEOT
Text
Viewer
Text
Viewer
These links explore the THEOT Text Viewer and How to Use It. Click the image on the left to open the website directly. Click the image on the right to see a video introducing the Text Viewer and How to Use it.
Best
Representative
Manuscripts
Representative
Manuscripts
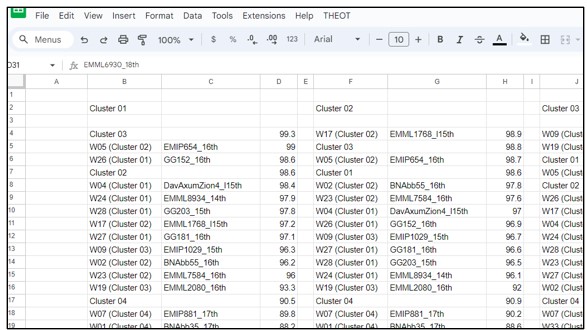
The spreadsheet shows a series of tabs that represent the various stages of processing the data with a view of identifying the best representative manuscript for each cluster. Click the image on the left to open a copy of the spreadsheet. Click the image on the right to see a video explaining how this data was produced or processed.
Esther: Sample, Best Representatives, Minor Recensions, Other Studies
- Sample of the Text: Esther 1:00A1-2, 1:6-9, 2:16-21, 3:5-7, 313f-g, 3:14-15, 4:1, 4:5-6, 4 17z, 5:3, 5:6, 6:8, 8:11-12, 8:12E:1, 8:17, 9:1-5, 9:16-18, 10:3k-l.
- Sample Size: 16.5% of the book.
- Sample of Manuscripts: 33. BL Add. 24991 (17th), BN Abb 35 (17th), BN Abb 55 (15-16th), EAP 704/1/5 (Dabra Abbey Monastery 005, e15th), 1595-1605), EAP 704 2/12 (Marawe Krestos 12, 16th), EMIP 0688 (1971), EMIP 0746 (e19th), EMIP 0881 (17th), EMIP 0924 (l19-e20th), EMIP 0975 (19th), EMIP 1029 (15-16th), EMIP 1051 (17th), EMIP 1088 (19th), EMIP 1123 (17-18th), EMIP 1128 (1895), EMML 0057 (15-16th), EMML 0819 (l18th), EMML 1481 (e17th), EMML 1768 (l15th), EMML 2080 (16th), EMML 6962 (Wollo Beta Giyorgis Church, 19th), EMML 7584 (16th), EMML 8846 (18th), Gunda Gunde 106 (1682-1706), Gunda Gunde 69+193 (15th), Hazarian 105 (20th), IES 77 (1934), UNESCO 02.09 (1912), UNESCO 02.13 (19th), UNESCO 02.18 (19th), UNESCO 02.22 (19th), UNESCO 10.12 (18th), UNESCO 10.36 (1931), Vat Cerulli 75 (1930/31) CHECK ON EAP 704 2/6 (Marawe Krestos 006, Jerusalem Archbishop 1E (1783).
- Number of Data Points Generated: 30,921.
-
Recension 1
- Earliest Attested 1 Best Representative – EAP 704.1.5 (e15th).
- Standardized 1 Best Representative – EMML 819 (l18th).
- Modern Textus Receptus 1 Best Representative – UNESCO 2.18 (19th).
-
Recension 2
- Earliest Attested 2 Best Representative – GG 69 (15th).
- Standardized 2 Best Representative – BL Add 24,991 (17th).
- Modern Textus Receptus 2 Best Representative – EMIP 924 (l19th).
- Minor Recension 3: Hazarian 105 (20th) and EMIP 975 (19th) represent a minor recension with only a 3% difference between them and a 13% degree of difference from the rest of the tradition.
